Перспективы использования потоковой модели вычислений в высокопроизводительных вычислительных системах
Левченко Н,Н., Змеев Д,Н,, Климов А.В., Окунев А.С., Стемпковский А.Л.
Введение
На современном этапе развития высокопроизводительных вычислительных систем сложилась парадоксальная ситуация – развитие аппаратных средств суперкомпьютерных технологий значительно опережает развитие программных средств (для параллельных вычислений). Это проявляется в том, что с ростом максимального числа вычислительных ядер в системе все сложнее становится их загрузить одной задачей, оставаясь в рамках традиционного фон-неймановского программирования.
Основные причины возникновения названной проблемы для классических вычислительных систем заключаются в следующем:
- Представление об алгоритме как о линейной последовательности действий (нити управления), то есть наборе последовательно исполняемых команд;
- Представление о взаимодействии процессора с памятью как о процессе, состоящем только из двух операций – чтения и записи по адресу в памяти;
- Представление о распределении вычислений как состоящем из различных уровней;
- Представление о распределении вычислений и данных как независимых друг от друга процессах.
Эти представления восходят еще к машине Тьюринга и фон-неймановской модели вычислений, в которой работа выполняется пошагово, то есть последовательно. Нить управления при работе имеет всегда только одну точку управления, поэтому будем называть ее одноточечной.
Для пояснения первого пункта вышеприведенного списка можно представить параллельный алгоритм в виде семейства одноточечных нитей, которые «взаимодействуют» друг с другом – одни передают сообщения, другие ждут и принимают. Возникает модель вычислений SPMD (Single-Program, Multiple-Data — одна программа, множество потоков данных) с протоколом передачи MPI (Message Passing Interface - интерфейс передачи сообщений) [1]. В модели вычислений GPGPU (General-purpose computation on graphics processing units - универсальные вычисления на графических процессорах) [2] – та же нить, только выполняемая над длинным вектором, или, иногда много нитей, по одной для каждого элемента, но уже не взаимодействующих. И как развитие этого возникает представление о вложенном параллелизме: одна нить распадается на многие, причем все они должны быть завершены до того, как родительская нить сможет продолжить работу. Последнее означает наличие барьера, который может приводить к простоям в работе вычислительной системы.
Вторая причина из списка требует решить следующий вопрос: как обеспечить прочтение другой нитью записанного операнда, и как узнать для другой нити, что операнды записаны и можно их читать.
Третий пункт из списка причин показывает, что необходимо распараллеливать программу на каждом из уровней распределения вычислений. К примеру, на конференции Intel Software Conference 2016 [3] представители фирмы Intel обозначили следующие уровни распределения вычислений для эффективного распараллеливания (на эти уровни распределения ориентированы программные продукты этой фирмы):
- уровень потоков (threads);
- уровень векторов (vectors);
- уровень вычислительных ядер (cores);
- уровень кластеров (clustering).
Всё это в значительной степени усложняет процесс создания программ, поскольку программист вынужден, фактически, распределять вычисления (распараллеливать программу) на каждом из данных уровней, обеспечивая при этом согласованность распределения по этим уровням.
Четвертой причиной возникновения проблем для традиционных вычислительных систем является то, что сами вычисления распределяются программистом независимо от распределения данных. При этом необходимо добиться минимизации обменов при передаче данных между вычислительными ядрами системы.
При наличии одной нити – проблем не возникает. Однако, при параллельной работе, когда таких нитей становится множество, ситуация полностью меняется. Альтернатива существующему подходу в высокопроизводительных вычислениях заключается в том, чтобы алгоритм представлять как многоточечный, содержащий много точек управления. Одна активная операция (команда) может «передать управление» нескольким операциям, тогда как новая операция для начала своей работы может требовать нескольких передач управления ей. Вместе с «передачей управления» логично всегда передавать некоторый объем требуемых данных.
Одним из способов преодоления проблемы эффективной загрузки всех вычислительных ядер системы одной задачей является переход к потоковой модели вычислений с динамически формируемым контекстом со специфическим механизмом управления – по готовности входных данных.
Потоковая модель вычислений
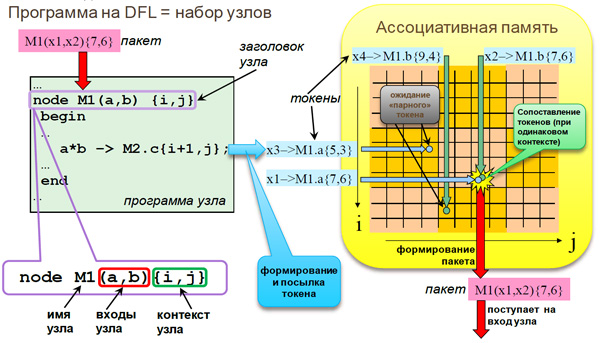
Рис. 1. Потоковая модель вычислений с динамически формируемым контекстом
Авторами предлагается потоковая модель вычислений с динамически формируемым контекстом (рис. 1), воплощенная в параллельном языке программирования DFL [4-6]. Программа на этом языке представляет набор описаний программных узлов, состоящих из заголовка узла и программного кода узла. Заголовок узла содержит имя программного узла, список входов и список атрибутов программы узла — контекст (индексы), который обеспечивает многократное повторение однотипных действий. Активация узла происходит тогда и только тогда, когда на все входы одного узла с определенным именем и контекстом придут все требуемые элементы данных — токены (структура данных, в состав которой входит предаваемый операнд, ключ с контекстом и адресом программного узла, маска и ряд других специальных признаков). В ассоциативной памяти происходит определение момента активации, которое является базовым принципом управления потоком данных. При активации выполняется последовательность команд программы узла, в которой вычисляются новые данные (исключительно на основе значений входов и атрибутов ключа), которые посылаются специальными операторами на другие узлы, причем атрибуты ключа адресата вычисляются непосредственно в этом же коде. Это означает, что работа производится в парадигме «раздачи» [7].
Суть проблемы фон-неймановского программирования для больших параллельных вычислительных систем заключается в том, что в ней реализуется парадигма «сбора». Для нее характерно, что только потребитель данных знает, какие данные ему нужны и где их взять, и сам их запрашивает, указывая имя переменной (рис. 2.а). В этих условиях аппаратуре трудно «предвидеть», какие данные будут нужны для тех или иных вычислений и в какой момент. Для более качественной стратегии перемещения данных более продуктивной будет использование парадигма «раздачи», в рамках которой производитель каждого нового значения знает, кому оно потребуется, и самостоятельно обеспечивает рассылку по нужным адресам. А получателю тогда остается пассивно «ожидать» прихода данных, ничего не зная об их источнике (рис. 2.б).
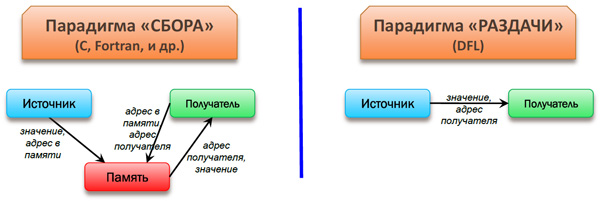
Рис. 2 Парадигмы «сбора» (а) и «раздачи» (б)
Парадигма «раздачи» является более экономной в плане числа обменов сообщениями: одно сообщение на каждое использование, тогда как в парадигме «сбора» используется одно сообщение на запись и еще по два на каждое использование (запрос и ответ).
Наиболее эффективным образом этот механизм реализуется через ассоциативную память (память с выборкой по содержимому). В этом случае обычная память не требуется. Всякое значение, необходимое для совершения операции программного узла просто должно быть отправлено другим каким-то узлом ему на один из входов. С другой стороны, когда на одни входы данные уже пришли, то до прихода остальных они должны где-то находиться в ожидании. Это и есть память, только теперь – ассоциативная, в ней «адресом» является имя/номер узла с набором его индексов. Этот «адрес» называется ключом.
Кроме хранения, в памяти также происходит сопоставление (сравнение) ключей токенов, необходимое для формирования групп токенов, направленных на один и тот же узел (с одинаковыми именем и атрибутами ключа) [6]. Такая группа токенов называется пакетом.
Интерфейс между вычислителем - исполнителем (многих) готовых активностей и этой «памятью» выглядит сложнее: вычислитель посылает в память данные с указанием ключа и номера-имени входа, а «память» добавляет их к накапливаемым на входах узлов, и, если возникает полный комплект, отправляет в исполнительное устройство задание на выполнение операции узла. Эта операция может представлять собой небольшую программу в обычной парадигме, которая с переданными ей данными отработает от начала до конца, без каких-либо ожиданий, и, возможно породит посылки новых данных в другие узлы, одновременно стирая (по умолчанию) использованные данные со своих входов.
Таким образом, решается много проблем: программа узла всегда имеет нужные ей данные локально, при этом программа не прерывается на подкачку дополнительных данных: активность возникает только тогда, когда все нужные для выполнения программы узла данные имеются в наличии. Затем активность исчезает, передав потенциалы активностей в виде результирующих данных другим узлам. Причем ответа ждать не надо, так как все такие сообщения (передачи токенов) односторонние.
Параллельная потоковая вычислительная система «Буран»
Потоковую модель вычислений с динамически формируемым контекстом реализует параллельная потоковая вычислительная система (ППВС) «Буран» [8].
ППВС представляет собой многоядерную масштабируемую вычислительную систему (рис. 3). Между ядрами в системе передаются единицы информации в виде токенов. Коммутация между ядрами осуществляется на основе значения номера ядра, вырабатываемого блоком хэширования на основе настраиваемой функции распределения вычислений.
Вычислительные ядра (рис. 3) в пределах одного кристалла организуются в вычислительные модули. Архитектура ППВС масштабируема и при увеличении числа ядер в системе падение реальной производительности на задачах со сложно организованными данными происходит существенно медленнее, чем при решении подобных задач на вычислительных системах с классической архитектурой. Это достигается, во-первых, за счет использования принципа потока данных, когда готовые к выполнению данные активируют выполнение программы узла; во-вторых, активируемому узлу для своего полного выполнения не требуется никаких дополнительных данных; в-третьих, узлы выполняются полностью независимо друг от друга и, в-четвертых, благодаря правильному выбору хэш-функции (функции распределения вычислений по группам ядер), сокращающей число межъядерных передач токенов.
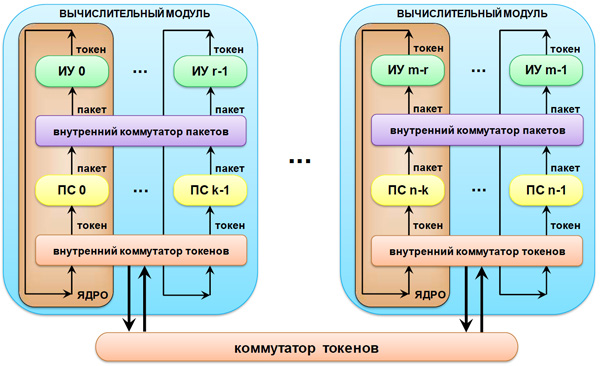
Рис. 3. Структурная схема ППВС
Вычислительный модуль системы конструктивно состоит из набора вычислительных ядер (фактически являясь многоядерным процессором), в состав которых входят:
- процессор сопоставления (ПС), в котором происходит сопоставление токенов по определенным правилам и формирование пакетов (структуры данных, которая содержит операнды, необходимые для активации вычислительного кванта – программы узла);
- исполнительное устройство (ИУ), в котором в соответствии с программой узла происходит обработка пакета и генерация новых токенов;
- блок хэш-функции, в котором осуществляется определение номера ядра, куда передается сформированный токен из исполнительного устройства;
- внутренний коммутатор токенов, который передает токен либо во внешнюю сеть, либо в свой процессор сопоставления;
- внутренний коммутатор пакетов, который передает пакет на любое свободное исполнительное устройство вычислительного модуля.
Особенности архитектуры ППВС «Буран»
Принципы распараллеливания программы, основанные на декомпозиции вычислений по данным, наиболее естественным образом обеспечивают асинхронное параллельное выполнение вычислений над независимыми элементами данных.
Основные преимущества предлагаемой системы:
- аппаратная поддержка параллельного выполнения вычислительных процессов выполняемой задачи;
- аппаратная поддержка управления распределением ресурсов вычислительных средств;
- возможность масштабирования системы на реальных задачах;
- конвейеризация вычислительного процесса;
- аппаратная поддержка синхронизации вычислительных процессов по данным;
- аппаратное выявление скрытого параллелизма программ;
- высокая реальная производительность при работе с разреженными данными и данными сложной логической организации.
Семантический разрыв между параллельным языком высокого уровня и предлагаемой архитектурой суперкомпьютера существенно ниже, чем в современных вычислительных системах. Как следствие, растет надежность программного обеспечения, продуктивность программирования, а также эффективность использования аппаратуры суперкомпьютера, сокращается время решения задачи и снижается себестоимость программного обеспечения.
Отличие ППВС «Буран» от классических dataflow-систем
Классические потоковые системы (dataflow) [9-11], которые разрабатывались в 80-х годах прошлого века, с целью преодоления проблем фон-неймановской модели вычислений, представляли собой по большей части вычислительные системы для выполнения традиционных (обычных) программ, но в новой модели вычислений. С этой же позиции создавались и новые высокоуровневые языки программирования с однократным присваиванием. Работы в этой области были свернуты потому, что в те времена еще не стояли так остро проблемы распараллеливания и был недостаточно высок технологический уровень развития вычислительной техники. В настоящее время проблема создания параллельных программ с высокой степенью масштабируемости выходит на первый план при наличии многоядерных (многопроцессорных) систем огромной мощности и интеграции вычислительной аппаратуры.
В основе системы, которая разрабатывается в ИППМ РАН (параллельная потоковая вычислительная система «Буран») лежит, прежде всего, совершенно новая модель вычислений, для которой создаются новые алгоритмы в рамках новой парадигмы программирования и на новом языке DFL.
Еще одним ключевым отличием от классических dataflow-систем является аппаратно поддержанная работа с динамически формируемым контекстом, что дает возможность программисту реализовывать новые принципы организации параллельных вычислительных процессов, повысить эффективность программирования, использовать контекст для распределения вычислений, а также использовать все поля контекста для программирования. В классических потоковых системах работа с контекстом была ограничена и не давала нужной степени свободы. В параллельной потоковой вычислительной системе контекст полностью доступен программисту [12].
Существенной проблемой классических dataflow систем была локализация вычислений. В ППВС она решается при помощи созданных функций распределения вычислений, которые в динамике обеспечивают равномерность распределения вычислений по физическим вычислительным ядрам системы, а также минимизацию обменов между вычислительными ядрами и, тем самым, повышают масштабируемость вычислительной системы и рост ее производительности [13].
Планирование вычислений, которое тесно связано с построением иерархии памяти сопоставления являлось еще одной проблемой классических потоковых систем. В параллельной потоковой вычислительной системе она решается благодаря применению функций распределения для этапов (группа токенов, которая необходима для выполнения определенного интервала вычислений; обычно этап связан с более или менее независимым действием, например, итерация в программе), которые в динамике разбивают вычислительный процесс на части с помощью небольшой настройки программистом. Это так называемая локализация вычислений во времени [14].
Кроме этого удалось избежать построения сопоставляющей памяти большого объема для хранения ключей и выстроена глобальная иерархия памяти.
В отличие от предыдущих классических потоковых систем, в ППВС реализуется развитая система команд процессора сопоставления, который аппаратно поддерживает функции языка высокого уровня.
Современные тенденции развития высокопроизводительных вычислений в архитектуре ППВС «Буран»
В архитектуре параллельной потоковой вычислительной системы «Буран» отчетливо проявляются следующие современные тенденции развития в области высокопроизводительных вычислений.
Многопоточность. Каждый узел – это отдельный поток и связь между узлами осуществляется только через передачу входных данных, причем потоки не приостанавливаются, а только завершаются. На одном многопоточном исполнительном устройстве могут одновременно выполняться несколько активаций узлов, которые никак не взаимодействуют между собой.
Мелкозернистость. Обычно в современных вычислительных системах стремятся увеличить размер гранулы, поскольку накладные расходы на запуск треда (потока), прием сообщения и приостановку треда высоки. В нашей системе эти накладные расходы минимизируются (перекладываются на аппаратуру).
Активные сообщения. Когда значения на других входах узла уже есть, токен, несущий входное значение, активирует вычисление. Поскольку любой токен может оказаться последним, каждый токен в нашей системе может считаться активным сообщением.
Процессор в памяти. Токен несет адрес и данные, и он может рассматриваться как обращение к памяти, сопровождаемое запросом на обработку:
- при поступлении последнего значения на входы узла с одним и тем же контекстом (адресом) происходит активация нужной программы узла;
- отсутствует проблема ожидания завершения записи данных в память;
- один из входов может принять адрес получателя результата;
- возможна непосредственная обработка на входе типа редукции.
Память сопоставления (ассоциативная). Обеспечивается функциональность, аналогичная механизму работы памяти с использованием full-empty bits [15].
Разделение доступа к данным и обработки данных (Decoupled Access-Execute) [16]. В нашей системе такая работа заложена непосредственно в самой модели вычислений.
Эксперименты
Для исследования работы ППВС «Буран» была разработана программная поведенческая блочно-регистровая модель [17], которая позволяет проводить эксперименты на различных задачах с изменением архитектуры системы. Была отлажена работа основных узлов и блоков системы на различных тестовых программах. Однако, учитывая то, что система ППВС начинает выигрывать в производительности у классических вычислительных систем только при больших размерностях задач и на большом количестве вычислительных ядер (до десятков и сотен тысяч), возникла необходимость в создании программного эмулятора ППВС [18] на высокопроизводительном кластере. В настоящее время данный эмулятор ППВС функционирует на суперкомпьютере «Ломоносов» [19].
Эмулятор ППВС позволяет пользователям пропускать параллельные программы в привычной программной среде, используя модель вычислений с управлением потоком данных, а также апробировать разработанные средства «аппаратного» масштабирования программ. Разработчикам же аппаратуры ППВС эмулятор требуется для отработки различных вариантов аппаратных решений и получения статистической информации для оценки эффективности от их внедрения.
На поведенческой блочно-регистровой модели ППВС «Буран» были проведены многочисленные эксперименты на различных задачах. На рис. 4 приведена суммарная загрузка ассоциативной памяти ключей в устройстве сопоставления на задаче «Быстрое преобразование Фурье» для последовательного алгоритма ввода данных (рис. 4.а) и алгоритма ввода данных методом чередования полувекторов (рис. 4.б) [20].
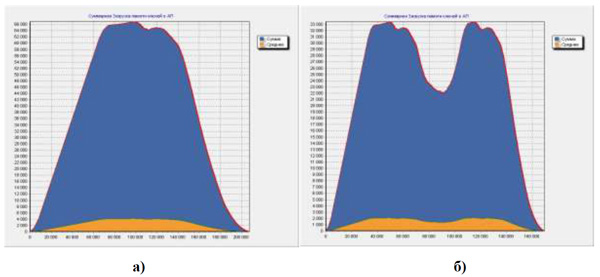
Рис. 4. Суммарная загрузка памяти ключей на задаче «БПФ» при последовательном вводе данных векторов (а) и при вводе данных чередованием полувекторов (б)
На рис. 5 приведены графики зависимости времени прохождения задачи от количества ядер на эмуляторе ППВС, работающем на суперкомпьютере «Ломоносов», для задачи «молекулярная динамика» (МД) [21]. Отчетливо видна тенденция сохранения степени масштабирования при увеличении числа ядер.
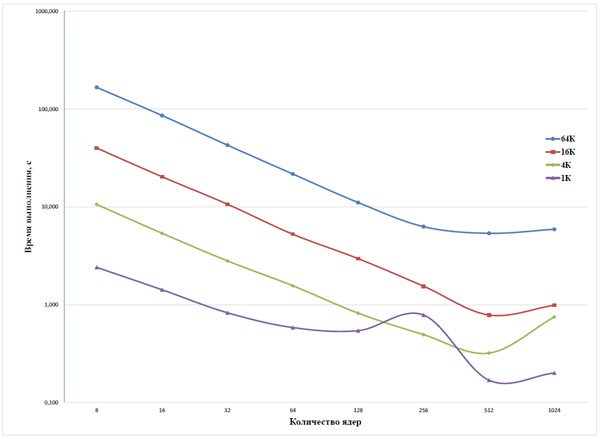
Рис. 5. Зависимость времени прохождения от количества ядер на суперкомпьютере «Ломоносов» для задачи МД (логарифмическая шкала)
Заключение
В настоящее время растет необходимость разработки масштабируемых вычислительных систем суперкомпьютерной производительности для работы в разных областях применения. При этом существует проблема низкой реальной производительности таких суперкомпьютеров. За рубежом тенденция создания суперкомпьютеров продолжает оставаться в рамках традиционной фон-неймановской модели вычислений. В статье предлагается перейти к нетрадиционной потоковой модели вычислений с динамически формируемым контекстом, что позволит решить основные проблемы, возникающие при создании вычислительных систем с большим количеством ядер.
Архитектура ППВС, реализующая такую модель вычислений, масштабируема, что позволяет эффективно решать большой круг актуальных задач с высокой реальной производительностью. Проведенные эксперименты подтверждают это.
Предлагаемая модель вычислений имеет уникальные особенности и преимущества, что позволяет надеяться на то, что в будущем она станет основной в области масштабируемых параллельных вычислений, а разрабатываемая аппаратура позволит подойти к созданию оригинальных отечественных высокопроизводительных вычислительных систем.
Литература
- Thomas Rauber, Gudula Rünger: Parallel Programming for Multicore and Cluster Systems. Second Edition, Springer 2013.
- http://gpgpu.org/ (Дата обращения 01.04.2017).
- https://istep2016.ru/ (Дата обращения 01.04.2017).
- Климов А.В., Левченко Н.Н., Окунев А.С., Стемпковский А.Л. Автоматическое распараллеливание для гибридной системы с потоковым ускорителем // журнал «Информационные технологии и вычислительные системы», 2011 г., №2, С. 3-11.
- Климов А.В., Окунев А.С. Графический потоковый метаязык для асинхронного распределенного программирования // Проблемы разработки перспективных микро- и наноэлектронных систем - 2016. Сборник трудов / под общ. ред. академика РАН А.Л. Стемпковского. М.: ИППМ РАН, 2016. Часть II. С. 151-158.
- А. В. Климов, Н. Н. Левченко, А. С. Окунев, А. Л. Стемпковский. Суперкомпьютеры, иерархия памяти и потоковая модель вычислений // Программные системы: теория и приложения: электрон. научн. журн. 2014. T. 5, № 1(19), с. 15–36. URL: http://psta.psiras.ru/read/psta2014_1_15-36.pdf
- Климов А.В., Левченко Н.Н., Окунев А.С., Стемпковский А.Л. Вопросы применения и реализации потоковой модели вычислений // Проблемы разработки перспективных микро- и наноэлектронных систем - 2016. Сборник трудов / под общ. ред. академика РАН А.Л. Стемпковского. М.: ИППМ РАН, 2016. Часть II. С. 100-106.
- Стемпковский А.Л., Левченко Н.Н., Окунев А.С., Цветков В.В. Параллельная потоковая вычислительная система – дальнейшее развитие архитектуры и структурной организации вычислительной системы с автоматическим распределением ресурсов // журнал «ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ», №10, 2008, С.2 – 7.
- Silc J., Robic B., Ungerer T. Asynchrony in parallel computing: From dataflow to multithreading // Parallel and Distributed Computing Practices. 1998. Vol. 1. № 1. P. 3-30.
- Lee Ben, Hurson A.R. Issues in Dataflow Computing //Advances in computers. 1993. Vol.37. P. 285-333.
- Ben Lee, Hurson A.R. Dataflow Architectures and Multithreading//Computer. 1994. Aug. V. 27, no. 8. P. 27-39.
- Змеев Д.Н., Климов А.В., Левченко Н.Н. Средства распределения вычислений в ППВС «Буран» и варианты реализации блока выработки хэш-функций // Проблемы разработки перспективных микро- и наноэлектронных систем - 2016. Сборник трудов / под общ. ред. академика РАН А.Л. Стемпковского. М.: ИППМ РАН, 2016. Часть II. С. 107-113.
- Климов А.В., Змеев Д.Н., Левченко Н.Н., Окунев А.С. Способы регулирования вычислений в параллельной потоковой вычислительной системе // Проблемы разработки перспективных микро- и наноэлектронных систем - 2014. Сборник трудов / под общ. ред. академика РАН А.Л. Стемпковского. М.: ИППМ РАН, 2014. Часть IV. С. 79-82.
- А.В. Климов, Н.Н. Левченко, А.С. Окунев "Преимущества потоковой модели вычислений в условиях неоднородных сетей" // Журнал "Информационные технологии и вычислительные системы", No 2, 2012, с. 36-45. ISSN 2071-8632.
- Vlassov V., Merino O.S., Moritz C.A., Popov K. (2007) Support for Fine-Grained Synchronization in Shared-Memory Multiprocessors. In: Malyshkin V. (eds) Parallel Computing Technologies. PaCT 2007. Lecture Notes in Computer Science, vol 4671. Springer, Berlin, Heidelberg.
- James E. Smith. Decoupled access/execute computer architectures / Proceeding ISCA '82 Proceedings of the 9th annual symposium on Computer Architecture. Pages 112-119.
- Levchenko N.N., Okunev A.S., Zmejev D.N. Development Tools for High-Performance Computing Systems Using Associative Environment for Computing Process Organization // In bk.: Proceedings of IEEE EAST-WEST DESIGN & TEST SYMPOSIUM (EWDTS’2016), Yerevan, Armenia, October 14-17, 2016. P. 359-362.
- Д.Н. Змеев, А.В. Климов, Н.Н. Левченко, А.С. Окунев, А.Л. Стемпковский. Эмуляция аппаратно-программных средств параллельной потоковой вычислительной системы «Буран» // Информационные технологии. 2015. Т. 21. №10. С. 757-762.
- Воеводин Вл.В., Жуматий С.А., Соболев С.И., Антонов А.С., Брызгалов П.А., Никитенко Д.А., Стефанов К.С., Воеводин Вад.В. Практика суперкомпьютера "Ломоносов" // Открытые системы, Москва: Издательский дом "Открытые системы", 2012, № 7, с. 36-39.
- Д.Н. Змеев, Н.Н. Левченко, А.С. Окунев, А.Л. Стемпковский. «Принципы организации системы ввода/вывода параллельной потоковой вычислительной системы», Программные системы: теория и приложения, 2015, 6:4(27), c. 3–28. URL http://psta.psiras.ru/read/psta2015_4_3-28.pdf.
- Khodosh L.S., Klimov A.V., Levchenko N.N., Okunev A.S., Zmejev D.N. Research of Asynchronous Algorithm for Molecular Dynamics Task on the PDCS "Buran" Models // In bk.: Proceedings of IEEE EAST-WEST DESIGN & TEST SYMPOSIUM (EWDTS’2016), Yerevan, Armenia, October 14-17, 2016. P. 327-330.
Об авторе: к.т.н.
-
-
к.т.н.
академик РАН, д.т.н.
ИППМ РАН, Москва, Россия
Материалы международной конференции Sorucom 2017
Помещена в музей с разрешения авторов
16 января 2019