Смешанная загрузка в современных СУБД
Эволюция в области информационных систем приобретает все более отчетливую направленность на объединение трех видов задач: оперативной обработки транзакций (OLTP), поддержки принятия решений (DSS) и пакетной обработки (batch processing), которые ранее искусственно отделялись. Одновременное исполнение задач смешанного характера, разделяющих общие вычислительные ресурсы и базы данных, носит название "оперативная обработка сложных транзакций" (OLCP). Управление ресурсами, оптимизация и администрирование в гибридной системе гораздо сложнее, чем в системе, ориентированной на решение единственной задачи, поскольку различные типы приложений предъявляют противоречивые требования к конфигурации. Тем не менее, преимуществом концепции смешанной загрузки является более полное соответствие задачам реальной жизни, а не удобству обработки данных. Например, экспертный анализ или загрузку/выгрузку данных пользователям хотелось бы производить в реальном времени, одновременно с вводом и модификацией данных. С применением параллельных архитектур, значительно ускоряющих обработку и обеспечивающих масштабируемость, ожидается появление систем, поддерживающих смешанную загрузку.
К сожалению, путь к реализации смешанной загрузки тернист. Часто производители СУБД предлагают архитектурные решения сервера, специфичные для определенных классов приложений. Например, сервер для обработки транзакций может строиться в предположении, что:
- наиболее часто используются короткие транзакции,
- обычно транзакции не используют одинаковые данные,
- операторы затрагивают обычно только несколько строк,
- только несколько таблиц имеют большие размеры или могут быть значительно изменены.
Реализация такого сервера опирается на физические методики сокращения операций с дисками, обработку небольших объемов данных в памяти, примитивный оптимизатор запросов, а также требования к приложениям - исключить конкуренцию запросов в использовании ресурсов и данных.
Для сервера системы принятия решений и оперативного анализа данных выдвигаются следующие требования:
- объем таблиц в целом не ограничен,
- часто требуется просмотр всех строк таблицы,
- число таблиц, участвующих в транзакции, может быть велико,
- обычно транзакции не модифицируют данные,
- высока вероятность разделения ресурсов и данных разными задачами.
Как следствие, необходимы мощный оптимизатор, эффективные методики сканирования и соединения таблиц, а также совершенные механизмы обеспечения параллельного доступа к данным нескольких приложений.
Сервер, ориентированный на пакетную обработку, полагается на истинность следующих предположений:
- обычно большие и сверхбольшие размеры таблиц,
- продолжительность транзакций может быть велика,
- обычно требуется просмотр и/ или модифицикация всех строк таблицы,
- одновременный запуск очень небольшого числа задач,
- характерно высокая загрузка процессора и заполнение оперативной памяти.
Помимо прочих, в режиме пакетной обработки выполняются административные операции, например, по реорганизации базы данных. Все это предъявляет требования к наименьшей избыточности базовых алгоритмов, определяющих скорость примитивных операций. В условиях смешанной загрузки производительность таких СУБД будет крайне низка, либо потребуется неприемлемо высокий уровень сопровождения баз данных и приложений.
Основные факторы, вовлеченные в эффективную реализацию универсальной системы, можно определить как:
- оптимизация запросов;
- эффективное управление ресурсами;
- параллельная обработка запросов.
Оптимизатор запросов
Возможности оптимизатора запросов в значительной мере определяют способности сервера эффективно обрабатывать SQL-операторы, затрагивающие несколько таблиц и множество строк. В частности, оптимизатор выбирает из нескольких вариантов оптимальный план выполнения запроса (рис. 5), в котором в виде дерева определены порядок перебора индексов и тип соединения таблиц на каждом шаге выполнения. Относительная стоимость запроса оценивается, исходя из предполагаемого количества операций с диском и операций сравнения в памяти. Оптимизатор должен строить свои оценки на статистике и на распределении данных в индексах, но не на синтаксисе записи SQL-запроса. При обработке сложных запросов в современных СУБД различные порции запроса могут выполняться параллельно или, наоборот, задерживаться планировщиком с целью улучшить общую производительность и использование ресурсов. Кроме того, используемый сервером баз данных параллелизм может резко изменить стратегии оптимизации. Например, при распараллеливании операции соединения таблиц иногда эффективнее обходиться без индексов, в других случаях для обеспечения одновременности доступа к данным необходимо тщательно учитывать уровень изоляции транзакций. Поэтому здесь необходима тесная кооперация между оптимизатором и подсистемой манипуляции данными, учитывающая все тонкости последующей обработки запроса в многопользовательском окружении.
Управление ресурсами
Оптимальное управление ресурсами обеспечивает поддержку прозрачности доступа к ресурсам в целом и эффективное использования каждого ресурса в отдельности. Поддержка прозрачности доступа очень актуальна. Например, создавая приложение в архитектуре клиент/сервер, разработчик не может и не должен строить предположений о том, как на самом деле взаимодействуют клиент и сервер. Использование в качестве среды коммуникаций сети или сегмента разделяемой памяти никак не должно влиять на идеи разработки, точно так же приложение не может как-то ограничивать коммуникационные решения СУБД. Если приложение и сервер баз данных находятся на одном компьютере, то пересылку сообщений между ними наиболее эффективным образом можно организовать через разделяемую память. Это может быть особенно эффективно для просмотра результатов обширной выборки с помощью курсора.
Одним из наиболее важных ресурсов является оперативная память. Оптимальное управление распределением памяти настолько же критично для производительности системы, как и уменьшение загрузки ОС, требующее многопотоковой архитектуры сервера баз данных. Приложения СУБД используют разделяемую память для сохранения контекста подключения, а также кэширования запросов и результатов. В некоторых серверах баз данных память отводится отдельно для каждого пользователя, и это значит, что считанные в нее страницы данных или индексов (единицы обмена СУБД с диском) будут недоступны другим пользователям до тех пор, пока они не считают эти данные повторно. В других архитектурах в память помещаются большие объемы информации о возможном откате транзакций (undo log) каждого пользователя, что противоречит используемому в многопотоковой архитектуре принципу минимальности хранимого контекста подключения, необходимого для эффективного управления потоками. Необходимы продуманные алгоритмы управления памятью, например, динамические разделяемые всеми приложениями буфера и кэш-области, наращиваемое по требованию распределение стека, функциональное разделение структур в памяти в соответствии с типами решаемых задач (рис. 8). Без этого архитектура сервера баз данных будет неспособна одновременно удовлетворить потребностям оперативной обработки транзакций, систем принятия решений и пакетной обработки.
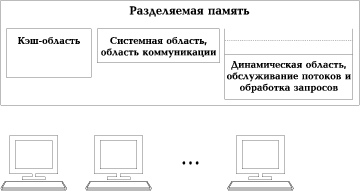
Рис. 8. Примерная схема разделяемой памяти.
Следующий момент, который стоит отметить, - исключение простаивания ресурсов процессоров. При необходимости выполнить вызов, блокирующий процесс, например, операцию ввода/вывода, есть смысл передать этот вызов как запрос другому процессу, а вместо ожидающего окончания операции потока собственный планировщик сервера баз данных может запустить следующий поток из очереди на обработку. При этом процесс, и, следовательно, обработка запросов не будут принудительно остановлены средствами ОС. В деятельности планировщика заданий внутри сервера важна также гранулярности той порции обработки, которая по каким-либо причинам, например, для лучшей изоляции транзакции, должна завершиться до передачи управления другому потоку. Обычно квант обработки имеет некий функциональный смысл - завершение SQL-запроса или атомарной операции. Если операция оказывается продолжительной, например, при соединении таблиц в сложном аналитическом запросе, то это может вызвать общую задержку системы, и совершенно недопустимо при совмещении задач принятия решений с чувствительными к времени реакции задачами обработки транзакций. В условиях смешанной загрузки предпочтительно использование серверов, поддерживающих достаточно стабильный размер кванта обработки.
Параллельная обработка запросов
Параллельная обработка является решением при низком быстродействии, характерном для сложных запросов и больших размерах обрабатываемой информации, например, массированно обновляемых крупных таблиц. За счет совмещения обработки небольших порций данных, параллелизм значительно улучшает производительность систем принятия решений и пакетной обработки. Эти улучшения позволяют включать сложные запросы в массовые транзакции, не жертвуя целостностью данных и изолированностью каждой транзакции, что было бы невозможным в традиционных системах. Имея приемлемое время реакции, аналитические (DSS) запросы не конкурируют с оперативной обработкой транзакций (OLTP) и не разрушают среду OLTP.