Шлюзы как средство интеграции баз данных. Практический подход.
Глеб Ладыженский
Введение
Практика показывает, что сейчас в целом завершается этап создания оперативных баз данных организаций. В том или ином виде (в виде персональных или промышленных реляционных БД) во многих из них сформировались центры актуальных данных, необходимых для оперативной работы. Темой сегодняшнего дня становятся технологии и программные продукты, способные обеспечить безболезненную интеграцию баз данных, возможность концентрации информации с целью оперативного анализа, долгосрочного планирования и прогнозирования деятельности организации, создание систем поддержки принятия решений (СППР).
В статье представлена одна из базовых технологий интеграции баз данных - технология шлюзов (gateways). Статья иллюстрирована практическими примерами, взятыми из реальной жизни. Рассматривается группа продуктов Transparent Gateway корпорации Oracle, включающая средства с широким набором возможностей и представляющая, на взгляд автора, наиболее сильное решение на рынке ПО промежуточного слоя (middleware) в категории интеграционного программного обеспечения (Database-Connectivity Tools см. классификацию [1]).
На самом деле задача статьи несколько шире. Хотелось бы рассказать, как принципы распределенных баз данных, сформулированные Э. Коддом, находят свое отражение в реальных проектах по интеграции разнородных баз данных и как на практике используются интеграционные средства Oracle, направленные на построение инфраструктуры СППР.
Проблемы интеграции баз данных
Разобщенные центры данных
Исторически в каждой конкретной организации сформировалось, как правило, несколько центров данных. В большинстве случаев это объясняется административными причинами. Важность информации как ресурса вполне осознавалась руководителями. Каждое подразделение стремилось создать свой собственный центр данных. В нем была сконцентрирована информация, находившаяся в ведении данного подразделения. Вовне она предоставлялась по официальным запросам, в электронном виде (на дискетах), но чаще просто на бумаге.
Однако период "феодальной раздробленности" заканчивается. Руководство любой уважающей себя организации не может допустить ситуации, когда информация о ее деятельности разобщена, скрыта внутри подразделений, ею распоряжающихся, и, следовательно, доступ к ней затруднен, а порой просто невозможен. В этой ситуации получение информации лицами, принимающими решения, обрастает массой бюрократических и технических сложностей, что практически не позволяет вести оперативную работу, поскольку выборка любой порции данных требует специальных административных усилий и отнимает массу времени.
В то же время каждый такой центр данных является точкой концентрации оперативной работы с данными. Часто, например, в рамках подобного центра функционирует система оперативной обработки транзакций (OLTP). Сложившаяся технология обработки данных, сделанные ранее значительные инвестиции в аппаратное и программное обеспечение не позволяют кардинально решить проблему их разобщенности путем механического переноса данных в центральную базу.
Тем не менее, новые задачи управления (СППР и системы хранилищ данных) требуют консолидации информации. Необходимы средства интеграции, которые обеспечивали бы не только унифицированный доступ к продолжающим функционировать центрам данных, но и позволяли создать инфраструктуру для доступа к данным, опирающуюся на единые стандарты и единые принципы сетевого взаимодействия.
Необходимо учитывать и процессы объединения (укрупнения посредством поглощения), которые происходят сегодня в России (особенно в банковской сфере). Несомненно, в число наиболее важных аспектов объединения информационных систем (которое неизбежно станет одним из этапов этого процесса) входит конструирование программной инфраструктуры новой организации с обязательным объединением разнородных баз данных.
Вообще говоря, построение осмысленной, архитектурно простой и эффективной программной инфраструктуры в типичной современной организации, где скопилось множество компьютеров различных моделей и эксплуатируются, как правило, СУБД от нескольких поставщиков, является ключевой задачей при создании информационной системы (ИС).
Унаследованные системы
Проблема унаследованных систем менее актуальна для России, нежели для Северной Америки и стран Западной Европы. Тем не менее в ряде российских компаний она весьма ощутима. Приобретенные ранее монолитные решения (в основном на базе мэйнфреймов) продолжают функционировать, например, как надежная платформа для систем OLTP, однако при решении новых задач (создания хранилищ данных и аналитических систем) акцент смещается на более популярные платформы (RISC/UNIX или Windows NT).
Новые задачи требуют доставки данных к месту их обработки. Необходим своего рода "программный канал" к унаследованным системам, который скрывал бы нижние уровни сетевого взаимодействия и обеспечивал свободный, "прозрачный" доступ к актуальным базам данных на мэйнфреймах или на иных частных (например, AS/400) вычислительных платформах.
Очевидно, что только задачами извлечения данных проблема не ограничивается. Возможна ситуация, когда потребуется синхронное обновление данных в нескольких БД, одна из которых принадлежит унаследованной системе. Так, например, процессинговый центр кредитных карточек может быть создан на основе RISC/UNIX-кластера с СУБД Oracle, в то время как автоматизированная система финансовой организации (Back Office) функционирует на мэйнфрейме. Владельцы карточек хотели бы иметь возможность перевода денег на основной счет в БД на мэйнфрейме и наоборот. Обновление в БД на обеих вычислительных установках возможно в рамках распределенной транзакции, что требует соответствующих программных средств.
Встречаются и задачи иного рода. Пусть, например, разрабатывается новое приложение (не имеет значения, с помощью каких средств), которое будет работать с БД Oracle. Предположим, что приложению потребуется, помимо доступа к БД Oracle, еще и доступ (возможно, и в режиме обновления) к БД на унаследованной системе. Адекватным решением будет использование шлюза, позволяющего работать с этой БД так, как будто это база данных Oracle.
Возможные решения
Спектр возможных решений по интеграции баз данных не ограничивается, разумеется, только технологией шлюзов. Причина столь пристального внимания к интеграционным средствам этого класса состоит в концептуальной и архитектурной простоте решения, четком ограничении функциональности, следствием чего является надежность систем на базе шлюзов. Кроме того, семейство продуктов Oracle Open Gateway вызывает доверие еще и тем, что это достаточно старые системы, прошедшие длительный период эксплуатации в серьезных условиях (в частности, на мэйнфремах) и, следовательно, их программный код тщательно выверен.
Несколько дополнительных слов о простоте программных решений. Создание современных информационных систем представляет собой прежде всего конструирование программной инфраструктуры из готовых компонентов (например, на основе сервисов ПО промежуточного слоя, как это предложено в работе [2]). Функциональность компонентов должна быть ясной, обозримой и существенно ограниченной рамками конкретной задачи. Чем проще устроен компонен, тем более предсказуемо его поведение. Шлюзы в этом смысле очень показательны - их исключительная простота гарантирует надежность эксплуатации.
Технология шлюзов Oracle
Характеристика продуктов
Корпорация Oracle разработала и уже в течение длительного времени предлагает пользователям семейство продуктов, называемое Oracle Open Gateway. Продукты Oracle Open Gateway предназначены для решения интеграционных задач и позволяют в совокупности с другими средствами Oracle (в частности, из семейства Oracle Universal Server) построить эффективную программную инфраструктуру современной ИС. Главная идея, положенная в основу технологии шлюзов Oracle, состоит в возможности простой интеграции СУБД и других изделий ведущих поставщиков ПО в программную среду на основе продуктов Oracle. Иными словами, технология шлюзов Oracle позволяет унифицировать доступ к данным (Oracle SQL) и хранимым процедурам, равно как и сетевое взаимодействие на прикладном уровне (Oracle SQL*Net) в вычислительной системе со сложной неоднородной архитектурой.
В семейство Oracle Open Gateways включены следующие продукты (рис. 1).
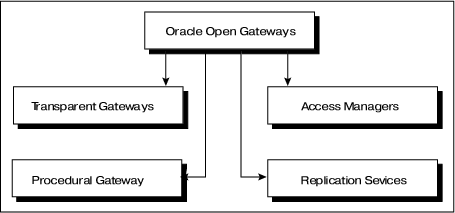
Рис. 1. Семейство продуктов Oracle Open Gateways.
Transparent Gateway (другое название SQL-based gateways) - группа продуктов (шлюзов),обеспечивающих доступ (посредством использования языка запросов SQL) к данным, хранящимся в отличных от Oracle базах данных. В настоящий момент поддерживается доступ к следующим базам данных: MS SQL Server, Sybase, Rdb, Ingres, Informix, Teradata, RMS, DB2/400, Image/SQL, DB2, SESAM, IBM DRDA, EDA/SQL. Кроме того, в этот набор включен шлюз к базам данных, поддерживающим стандарт ODBC. То есть, если к некоторой СУБД существует драйвер ODBC, то данные из нее могут быть извлечены посредством языка запросов Oracle SQL с использованием продукта Oracle Transparent Gateway ODBC. Собственно, определение назначения продуктов группы Transparent Gateway содержится в самом названии группы шлюзы обеспечивают прозрачный доступ к "чужим" данным, то есть позволяют работать с ними (с данными) так, как будто это данные в формате Oracle. Далее мы будем для простоты называть продукты этой группы прозрачными (transparent) шлюзами.
Procedural Gateways - (процедурные шлюзы) группа продуктов (шлюзов), обеспечивающих обработку вызовов удаленных процедур, причем удаленные процедуры определены и выполняются в отличной от Oracle программной системе.
Access Managers (менеджеры доступа) - группа продуктов (пока включает только один программный продукт под названием Access Manager for AS/400), основным назначением которых является поддержка доступа "чужих" приложений посредством языка запросов SQL к базам данных Oracle.
Replication Services (сервисы репликации) - группа продуктов,обеспечивающих репликацию данных из БД Oracle в "чужие" базы данных (равно как и репликацию из "чужих" баз данных в БД Oracle). Для репликации используются прозрачные шлюзы к соответствующим базам данных.
В свете сказанного выше об актуальности задач интеграции баз данных, из всего семейства шлюзов Oracle наибольший интерес представляет группа Transparent Gateways, поэтому настоящий текст целиком посвящен рассмотрению технологических аспектов прозрачных шлюзов. Процедурным шлюзам предполагается посвятить отдельную статью. Помимо прозрачных шлюзов, несколько слов будет сказано о сервисе репликации (в контексте решения задачи репликации данных из "чужих" баз данных в Oracle).
Технологию прозрачных шлюзов Oracle мы рассмотрим на примере одного из пилотных проектов, выполненных в 1998 году сотрудниками Technology Solution Group (технологического подразделения Oracle Russia) для крупной финансовой организации. Мы решили использовать прозрачные шлюзы в качестве каналов для доставки данных из двух источников в хранилище данных, макет которого предполагалось разработать в рамках пилотного проекта. То есть в данном проекте шлюзы самостоятельного интереса, казалось бы, не представляли по вполне понятным причинами это был тематический DSS-ориентированный проект. Однако работа со шлюзами дала обширный материал для размышлений и обобщений, результатом которых и стала данная статья. По моему мнению, прозрачные шлюзы представляют несомненный практический интерес для проектов корпоративных ИС в качестве средства интеграции баз данных. Теоретически прозрачные шлюзы важны как яркие представители ПО промежуточного слоя.
Перед тем, как перейти к рассмотрению конкретных продуктов и технических решений, необходимо объяснить суть технологии сервер/сервер и ее особенности для разрешения проблем интеграции баз даных.
Технология сервер/сервер
Рассмотрим типичную для современной организации задачу. Программная инфраструктура включает несколько баз данных различных форматов. На компьютерах-клиентах выполняется приложение, в общем случае запрашивающее данные из нескольких БД.
Возможны следующие варианты решения. Во-первых, для организации доступа приложения к базам данных можно использовать частный интерфейс прикладного программирования (для каждой БД свой собственный).Нетрудно видеть, что такое решение не годится. Детали доступа к БД определены в приложении, что крайне неудобно как при разработке (необходимо помнить особенности работы с каждой из СУБД), так и при эксплуатации.
Доступ приложения к данным должен быть безусловно унифицирован. Необходимо использовать обобщенный API, скрывающий особенности баз данных, к которым выполняется доступ. Таким образом, мы хотим добиться следующего. Во-первых, мы хотели бы иметь доступ к различным базам данных. Во-вторых, для реализации такого доступа мы хотели бы использовать унифицированный API, который скрывал бы особенности баз данных и детали сетевого взаимодействия клиент/сервер. Вопрос в том, где будет размещен компонент, обеспечивающий унификацию доступа к базам данных (далее для краткости будем называть его компонентом доступа к БД) и каким образом он это будет делать.
Данный компонент можно разместить либо на клиенте, либо на сервере. Наиболее очевиден первый вариант решения. На компьютере-клиенте, где выполняется приложение, размещается, помимо компонента доступа к БД, еще и сетевые компоненты (обобщенное название X Net Client, где X название конкретной СУБД), обеспечивающие доступ к каждой из баз данных. Так, если приложение работает с базами данных Oracle и Informix, то на компьютер-клиент должны быть установлены продукты Oracle SQL*Net Client и Informix-Net Client.
Недостатки подобного решения очевидны.
Во-первых, компьютер-клиент становится просто неприлично толстым. Мало того, что он должен поддерживать компонент представления и прикладной компонент (классическая RDA-модель). Помимо этого, на него дополнительно возлагается унификация доступа к базам данных (вся синтаксическая и, возможно, семантическая трансляция "обобщенный SQL диалект SQL") для каждой из баз данных. Перегруженность клиента системной функциональностью никак не укладывается в современные представления об архитектуре клиент/сервер.
Во-вторых, наблюдается множественность сетевых протоколов прикладного уровня, обеспечивающих доступ к базам данных (для Oracle это будет SQL*Net, для Informix Informix-Net и т.д.). То есть, мы добились унификации интерфейса прикладного программирования и теперь приложение обращается к любой базе данных на одном и том же языке "обобщенном SQL". Однако сетевые протоколы не унифицированы, что порождает дополнительные проблемы. Так, всегда удобнее защищать (например, средствами шифрования) один протокол, нежели множество, то же можно сказать и об администрировании. Дело в том, что ныне компонент X Net у большинства поставщиков СУБД представляет собой развитую сетевую подсистему со специализированными сервисами (сервисом имен, например) и ее нормальное администрирование требует специальных знаний и навыков.
Примером интеграции баз данных на стороне клиента является прямая реализация (то есть клиент/сервер) подхода на основе стандарта ODBC. Напомним, что ODBC позволяет программам, работающим в среде Windows, взаимодействовать (посредством операторов языка SQL) с различными СУБД, как с персональными, так и с многопользовательскими, функционирующими в различных операционных системах. Фактически, интерфейс ODBC универсальным образом отделяет чисто прикладную, содержательную сторону приложений (обработка электронных таблиц, статистический анализ, деловая графика) от собственно обработки и обмена данными с СУБД. Основная цель ODBC c сделать взаимодействие приложения и СУБД прозрачным, не зависящим от класса и особенностей используемой СУБД (мобильным с точки зрения используемой СУБД).
Не стоит жестко связывать интеграцию баз данных на стороне клиента и доступ к БД на основе ODBC. Дело в том, что ODBC можно использовать и на стороне сервера с использованием продукта Oracle Transparent Gateway for ODBC (TGODBC), о котором также будет рассказано в статье.
С ODBC можно работать также и в ОС UNIX.
Интерфейс ODBC обеспечивает взаимную совместимость серверных и клиентских компонентов доступа к данным. Для реализации унифицированного доступа к различным СУБД было введено понятие драйвера ODBC (представляющего собой динамически загружаемую библиотеку в терминологии Windows).
ODBC-архитектура (рис. 2) включает четыре компонента:
- приложение;
- менеджер драйверов (Microsoft Driver Manager);
- драйверы к каждой из СУБД;
- источники данных.
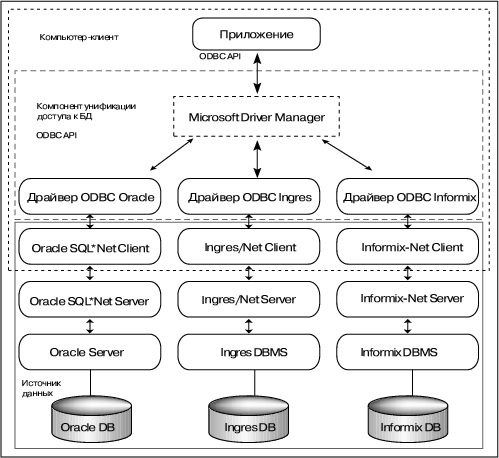
Рис. 2. Архитектура ODBC.
Приложение вызывает функции ODBC для выполнения операторов SQL, получает и интерпретирует результаты; менеджер драйверов динамически загружает ODBC-драйверы, когда этого требует приложение; ODBC-драйверы обрабатывают вызовы функций ODBC, передают операторы SQL СУБД и возвращают результат в приложение. Собственно, приложение черпает данные из источника данных объекта, скрывающегоот приложения детали СУБД и сетевого интерфейса, расположение и полное имя базы данных и т.д.
Другим возможным решением является размещение компонента доступа к БД на стороне сервера (рис. 3). Приложение на компьютере-клиенте взаимодействует с сервером посредством Oracle SQL. Для организации сетевого взаимодействия клиента и сервера используется SQL*Net (Net8). Клиент обращается к любым базам данных, доступным в рамках корпоративной сети, как к базам данных Oracle. Обращение к базам данных других форматов полностью прозрачно для клиента, то есть клиент ничего не знает о том, на каком из компьютеров-серверов расположена искомая база данных и в каком она формате. Однако обращение к базе данных происходит не напрямую (как в случае с ODBC), а опосредованно, через сервер Oracle (как это сделано технически, будет рассказано ниже). Именно этот факт дает основание говорить о том, что в данном случае имеет место технология сервер/сервер. То есть клиент обращается к Oracle Server, а тот взаимодействует с сервером другой базы данных.
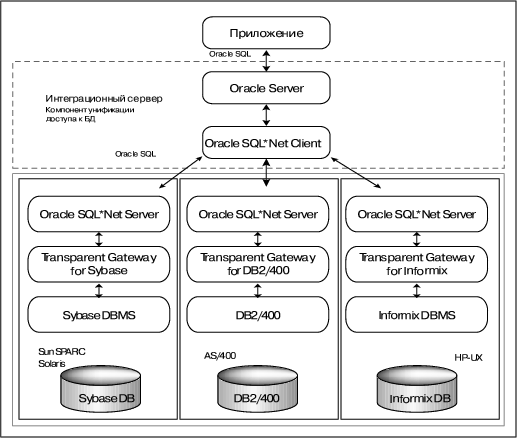
Рис. 3. Архитектура сервер/сервер.
Таким образом, интеграция баз данных на уровне сервера предполагает:
- выделение некоторого компьютера, который выполнял бы роль интеграционного сервера баз данных (ввиду распространенности и популярности логично было бы установить на него СУБД Oracle);
- единообразный способ доступа приложения на компьютере-клиенте СУБД к интеграционному серверу БД;
- использование специализированных средств (шлюзов) для организации доступа сервера Oracle к базам данных других форматов.
Отметим, что два подхода к интеграции баз данных (на стороне клиента и на стороне сервера) выделены в статье исключительно для объяснения специфики работы продуктов группы Oracle Transparent Gateway. Вообще говоря, при подготовке статьи не ставилась задача детального анализа достоинств и недостатков решений по интеграции баз данных (ODBC, EDA/SQL, IBM DRDA).
Архитектура шлюза
Как было отмечено выше, архитектура шлюза в данной статье объясняется на примере пилотного проекта финансовой организации. В организации существуют и развиваются два центра данных. Один из них представляет собой систему OLTP на базе компьютера IBM AS/400, на котором функционирует СУБД DB2/400. Большая часть актуальных данных финансовой организации хранится в базах данных DB2/400 (версия СУБД DB2 производства IBM, реализованная на компьютерах AS/400). Другой центр обработки данных опирается на сервер на платформе Intel под управлением ОС Windows NT с СУБД MS SQL Server (версия 6.5). Собственно, задача пилотного проекта заключалась в отработке технологической схемы "источники данных (БД MS SQL Server, DB2/400) > сервер очистки и согласования данных > хранилище данных > витрины данных > приложения OLAP" на основе продуктов и технологий Oracle.
Далее мы будем рассматривать фрагмент информационной системы финансовой организации, в рамках которого выполнялись все работы. Системно-техническая инфраструктура была представлена следующими компьютерами:
- AS/400 под управлением OS/400 (СУБД DB2/400);
- Сервер Intel/Pentium под управлением Windows NT (СУБД MS SQL Server);
- IBM RS/6000 под управлением AIX (интеграционный сервер, СУБД Oracle8);
- Компьютер-клиент Intel/Pentium под управлением Windows NT.
Компьютеры были связаны в сеть Token Ring, поддерживался протокол TCP/IP.
Программная инфраструктура фрагмента ИС была образована следующими компонентами:
- Приложение (выполняется на компьютере-клиенте);
- Сервер Oracle (Oracle7 или Oracle8, функционирует на интеграционном сервере);
- Шлюзы Transparent Gateway for DB2/400 (TGDB2400),
- Transparent Gateway for Microsoft SQL Server (TGMSQL); SQL*Net или Net8.
Подобная программная инфраструктура является типовой для систем, обеспечивающих интеграцию баз данных посредством прозрачных шлюзов. Разумеется, сами шлюзы будут зависеть от того, к каким базам данных они обеспечивают доступ.
Функционально прозрачный шлюз представляет собой своего рода "интеллектуальный программный канал" для доступа к базам данных иных, нежели Oracle, форматов. Не следует думать, что шлюзу известен "формат" этих БД и обращение к данным идет "в обход" СУБД, то есть напрямую. Напротив, для извлечения данных из искомой базы шлюз обращается непосредственно к СУБД (например, посредством SQL, если речь идет о реляционной СУБД), которая и обеспечивает требуемый доступ. Назовем для краткости эту пару (искомая база данных и СУБД, обеспечивающая доступ к ней) целевой системой (target system).
Схема функционирования прозрачного шлюза представлена на рис. 4.
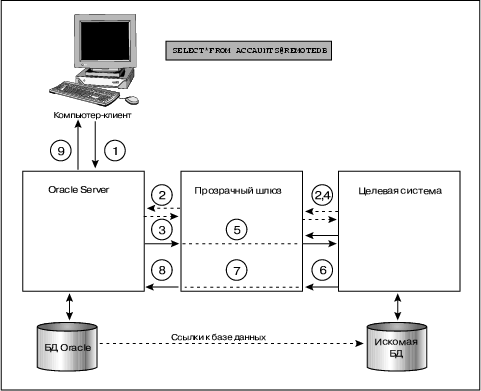
Рис. 4. Схема функционирования прозрачного шлюза.
Последовательность действий при доступе к целевой системе такова:
- Приложение направляет запрос серверу Oracle.
- (Этот шаг не является обязательным.) Возможны ситуации, когда шлюз должен отыскать входные характеристики пользователя в словаре данных целевой системы и разрешить ему доступ к ней.
- Сервер Oracle направляет запрос шлюзу.
- Шлюз взаимодействует с целевой системой, которая разрешает доступ пользователя к объекту целевой системы.
- Шлюз транслирует операторы Oracle SQL в SQL целевой системы.
- Шлюз получает данные из целевой системы.
- Шлюз конвертирует полученные данные в формат Oracle.
- Шлюз возвращает результат запроса серверу Oracle.
- Сервер Oracle возвращает результат запроса приложению.
С помощью шлюза можно не только работать с данными посредством запросов SQL, но и вызывать удаленные хранимые процедуры, принадлежащие целевой системе. Для этого используются прозрачные шлюзы с процедурными возможностями.
Необходимость использования таких шлюзов возникает в том случае, когда помимо работы с данными посредством SQL-запросов требуется вызывать удаленные хранимые процедуры целевой системы.
Пусть, например, мы используем СУБД DB/2 в целевой системе и для реализации некоторой прикладной функциональности был использован механизм хранимых процедур. Пусть, далее, приложению, работающему с БД Oracle, порой необходимы данные из DB/2. Это же приложение иногда должно обращаться к хранимым процедурам целевой системы.
Схема работы прозрачного шлюза с процедурными возможностями представлена на рис. 5.
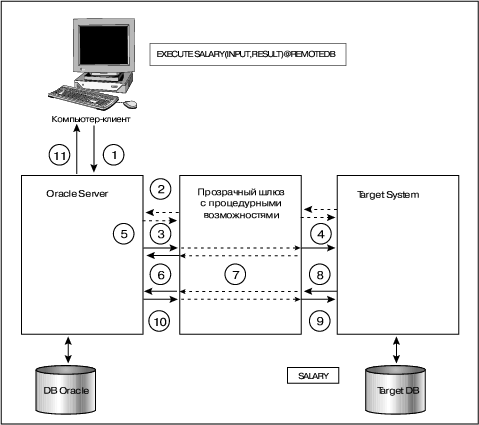
Рис. 5. Схема функционирования прозрачного шлюза с процедурными возможностями.
Последовательность действий такова:
- Приложение вызывает хранимую процедуру SALARY (считая, что она выполняется сервером Oracle, тогда как на деле это процедура целевой системы).
- (Этот шаг не является обязательным.) Возможны ситуации, когда шлюз должен отыскать входные характеристики пользователя в словаре данных целевой системы и разрешить ему доступ к ней.
- Сервер Oracle запрашивает описание хранимой процедуры SALARY.
- Запрос через шлюз направляется целевой системе.
- Целевая система возвращает через шлюз ответ (описание хранимой процедуры SALARY).
- Сервер Oracle направляет запрос на выполнение хранимой процедуры SALARY.
- Запрос через шлюз направляется целевой системе.
- Выполняется хранимая процедура SALARY.
- Шлюз получает код возврата процедуры и результат, конвертирует данные в формат Oracle.
- Шлюз возвращает результат серверу Oracle.
- Сервер Oracle возвращает результат процедуры приложению.
С точки зрения размещения на компьютерах-серверах, прозрачные шлюзы могут быть сконфигурированы как:
- Cтационарные (host-based)
- Удаленные (remote-based)
В системе со стационарным шлюзом последний устанавливается на тот компьютер, где функционирует целевая система. Конфигурация с удаленным шлюзом предполагает размещение шлюза не на компьютере с целевой системой (например, на интеграционном сервере). Особо отметим, что речь идет именно о возможном варианте конфигурации шлюза (а вовсе не о его типе). Так, продукт TGMSQL может быть сконфигурирован и как стационарный, и как удаленный, а вот TGDB2400 можно установить только в стационарном варианте. В обоих вариантах конфигурации через шлюз можно получить доступ одновременно к нескольким источникам данных.
Архитектура прозрачного шлюза в стационарной конфигурации (реальная конфигурация ИС организации) представлена на рис. 6. На AS/400, наряду со шлюзом, функционирует также система оперативной обработки транзакций, к которой возможно одновременное обращение нескольких сотен пользователей (на рисунке она не показана). Стационарное размещение шлюза в целом не сказывается на производительности OLTP-системы (шлюз оформлен как несколько фоновых процессов), но, конечно, требует дополнительных системных ресурсов. Отметим, что сетевой протокол прикладного уровня для взаимодействия как "компьютер-клиент/интеграционный сервер", так и "интеграционный сервер/компьютер целевой системы" унифицирован и представляет собой Oracle SQL*Net.
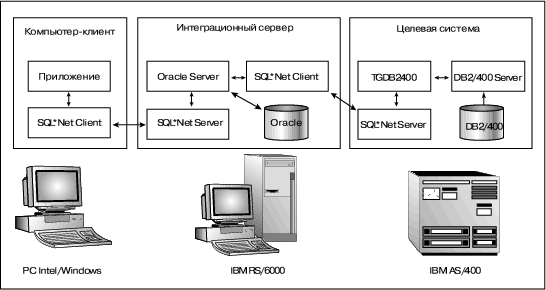
Рис. 6. Стационарная конфигурация прозрачного шлюза.
На наш взгляд, унифицированный (то есть распространенный по всей сети) сетевой протокол прикладного уровня является важнейшей характеристикой грамотно спроектированной информационной системы.
Рассмотрим теперь средства Oracle, позволяющие обращаться к удаленным базам данных. Имеются в виду ссылки к базам данных (database link). Используя этот механизм, Oracle упрощает взаимодействие между базами данных в распределенной системе. Ссылка к БД представляет собой объект базы данных Oracle, который задает местонахождение удаленной БД и параметры доступа к ней.
Поясним детали на примере. Пусть в целевой системе (в конфигурации, представленной на рис. 6) существует база данных с именем accounts. Необходимо обеспечить доступ к ней (конкретно, к таблице clients) с компьютера-клиента. Для этого надо выполнить следующие шаги (предполагается, что все изображенные на рис. 6 программные компоненты уже установлены).
- Обеспечить подключение интеграционного сервера к компьютеру целевой системы, используя протокол TCP/IP, и сконфигурировать SQL*Net для AS/400 (по завершении этой процедуры должен сработать ping к AS/400). Эта задача является сетевой, по сути не имеет отношения к рассматриваемой тематике, решается достаточно просто и по этой причине ее детали поясняться не будут. В случае с AS/400 возможно подключение и посредством протокола APPC/LU6.2, однако в пилотном проекте был применен TCP/IP.
- Подключиться с интеграционного компьютера к AS/400 по SQL*Net (в конце этой процедуры должна успешно выполниться утилита tnsping, предназначенная для проверки связи по SQL*Net). Рассмотрим этот этап более подробно, так как мы будем ссылаться на него далее.
В файл TNSNAMES.ORA на интеграционном сервере необходимо добавить еще один дескриптор:
Листинг 1
AS400 = (DESCRIPTION= (ADDRESS=(PROTOCOL=TCP (PORT=1521) (HOST=host_name)) (CONNECT_DATA=(SID=csi_name)))
Ссылки к базам данных
Ссылку к удаленной БД необходимо создать, используя следующий оператор SQL:
Листинг 2
CREATE PUBLIC DATABASE LINK dblink CONNECT TO userid IDENTIFIED BY password USING 'tns_service_name'
где
- dblink - полное имя удаленной базы данных
- userid, password - параметры пользователя, от имени которого осуществляется доступ к удаленной базе данных (в нашем примере к базе данных DB2/400 подназванием accounts). Этот пользователь должен быть создан администратором баз данных DB2/400 и ему должны быть предоставлены соответствующие привилегии по доступу к данным.
- tns_service_name - должно соответствовать имени дескриптора в файле TNSNAMES.ORA.
Таким образом, если в базе данных accounts определен пользователь gtuser с паролем dbtest, то ссылка к ней может быть создана следующим оператором SQL
При практической работе рекомендуется от имени системного администратора запустить на интеграционном сервере SQIL*Plus и все дальнейшие операции выполнять с его помощью.
Листинг 3
CREATE PUBLIC DATABASE LINK remotedb CONNECT TO gtuser IDENTIFIED BY dbtest USING 'AS/400'
Единожды создав ссылку к удаленной базе данных, можно многократно пользоваться ею для доступа к БД. Пусть, например, необходимо выбрать все строки из таблицы clients базы данных accounts (она нам доступна теперь через ссылку remotedb):
Листинг 4
SELECT * FROM clients.accounts@remotedb
Несколько слов о разграничении доступа к удаленной БД. Как видно из оператора CREATE DATABASE LINK, созданная ссылка явным образом идентифицирует пользователя, от имени которого через эту ссылку будет осуществляться доступ к удаленным базам данных целевой системы. Важно понимать, что этот пользователь не является пользователем Oracle он задан и существует как специальный пользователь целевой системы, от имени которого к ее базам данных будет выполнен доступ из других систем. Поэтому DBA целевой системы должен сообщить его входные параметры DBA Oracle до создания ссылки. Если же в операторе CREATE DATABASE LINK параметры пользователя не указаны, то используется текущее имя пользователя Oracle и в этом случае необходимо, чтобы оно совпадало с именем пользователя целевой системы.
Определение ссылок к базам данных хранится в словаре Oracle. Представление (view) словаря с именем USER_DB_LINKS содержит определение ссылок к БД, созданных текущим пользователем, тогда как представление ALL_DB_LINKS позволяет увидеть характеристики всех ссылок (если на то администратором БД предоставлены соответствующие права).
Так как созданная нами ссылка является общедоступной (public), ее может использовать любой пользователь Oracle на интеграционном сервере для доступа к БД accounts. Можно создать и частную (private) ссылку к удаленной базе данных. С точки зрения безопасности правильно было бы использовать только частные ссылки к удаленной БД и выполнять сам доступ к ней только от имени специально выделенного пользователя.
Ниже будет рассмотрено несколько способов доступа к удаленной БД посредством ссылок. Отметим интересный способ именования удаленных баз данных, который обеспечивается в Oracle с помощью синонимов (synonym). Синоним это новое упрощенное имя таблицы базы данных (в том числе удаленной). Как мы видим из приведенного выше запроса, полная прозрачность обращения к удаленной базе данных пока не достигнута, так как мы вынуждены указывать в явном виде ссылку к ней. Для достижения цели необходимо создать синоним clients:
Листинг 5
CREATE PUBLIC SYNONYM clients FOR clients.account@remotedb
Теперь приведенный выше запрос можно сформулировать проще:
Листинг 6
SELECT * FROM clients
Отметим, что был создан общедоступный синоним. Это означает, что любой пользователь Oracle, зарегистрированный на интеграционном сервере, может использовать синоним clients для доступа к удаленной базе данных.
Кодировки
В неоднородной информационной среде неизбежно возникают проблемы с кодировками. Так, в данном случае мы имели дело с вычислительной установкой AS/400, для которой стандартной кодировкой является EBCDIC, в то время как на UNIX-компьютерах используется кодировка ASCII. Шлюз выполняет автоматическое преобразование кодировок EBCDIC-ASCII. Сложнее было с символами русского языка.
Известно, что Oracle поддерживает стандарт NLS. Группа продуктов Oracle Transparent Gateways не является исключением. Правильно установив параметры NLS на интеграционном сервере и параметры NLS шлюза, можно добиться корректной обработки символов русского языка. На интеграционном сервере мы использовали стандартную для Oracle на UNIX-компьютерах кодировку ISO8859-5. Параметры NLS шлюза TGDB2400 устанавливаются с консоли AS/400 командой CHGORATUN, параметры Oracle SQL*Net командой CHGORANET. Синтаксис дляспецификации языковых параметров в обоих случаях одинаков и выглядит следующим образом:
Листинг 7
language [_territory.character_set]
Значение параметра character_set должно быть выбрано из таблицы Supported Character Set. Наиболее подходящим казался набор символов Western European (код WE8EBCDIC37). Однако с ним шлюз TGDB2400 выполнял преобразование кодов неверно. По рекомендации коллег мы установили значение CL8EBCDIC1025 - кодировка русского языка, используемая Oracle на мэйнфремах, несмотря на то, что этой кодировки в таблице указано не было. После этого шлюз заработал нормально. Было необходимо, чтобы данные в целевой системе имели кодировку CL8EBCDIC1025.
Доставка данных на интеграционный сервер
После того, как мы установили и наладили шлюзы к DB2/400 и MS SQL Server, необходимо заняться собственно передачей данных. Существует несколько вариантов решения.
Можно создать на интеграционном сервере временную таблицу, выбрав в нее все данные из исходной (в рамках одного оператора SQL), например:
Листинг 8
CREATE TABLE oracle_table AS
SELECT * FROM db2_table.db2_database@dblink
Для заполнения временной таблицы можно использовать оператор INSERT:
Листинг 9
INSERT INTO oracle_table
SELECT * FROM db2_table.db2_database@dblink
Однако мы хотели бы обеспечить периодическую "подкачку" данных на интеграционный сервер из целевой системы. Наиболее очевидным подходом является использование одного из простейших механизмов репликации Oracle механизма моментальных копий или снимков (snapshot). Ниже мы будем говорить только о необновляемых снимках.
Следуя определению Oracle, снимок представляет собой предназначенную только для чтения копию главной таблицы (master table), расположенную на удаленном узле. К снимку можно обращаться с запросами на выборку, но нельзя его обновлять: обновляется главная таблица, а затем изменения автоматически переносятся на снимок.
Рассмотрим пример, где:
- cusomers - имя снимка;
- clients - имя главной таблицы;
- accounts - имя исходной базы данных;
- remotedb - ссылка к исходной базе данных.
Листинг 10
CREATE SNAPSHOT customers
PCTREE 5
PCTUSET 60
TABLESPACE users
STORAGE (INITIAL 50K NEXT 50K)
REFRESH COMPLETE NEXT SYSDATE+1
AS
SELECT * FROM client.account@remotedb
Данный оператор создает снимок с таблицы удаленной базы данных. REFRESH специфицирует режим обновления (refresh) снимка. Значение COMPLETE необходимо задавать, когда предполагается полное обновление снимка, то есть данные из исходной таблицы целиком переносятся в снимок. Значение FAST соответствует так называемому "быстрому" обновлению, когда в снимок помещаются не целиком все данные из исходной таблицы, а только изменения, имевшие место с момента последнего обновления. Возможен также режим FORCE, когда Oracle определяет по ситуации, возможно ли применить режим быстрого обновления и, если да, использует его; в противном случае действует режим COMPLETE.
Здесь речь идет об автоматическом обновлении снимка, в отличии от обновления (update), выполняемого приложением над таблицами. Как было сказано выше, эту операцию над необновляемыми снимками выполнять нельзя.
NEXT задает интервал между автоматическими обновлениями. Значение SYSDATE+1 соответствует обновлению с интервалом времени в сутки. Первое обновление производится в момент создания снимка.
Смысл созданного снимка таков. На интеграционном сервере в базе данных Oracle под именем customers создан "образ" таблицы clients в удаленной базе данных accounts. В момент создания в него помещены все данные из таблицы clients. После этого OLTP-система, работающая с базой данных DB2/400, может вносить в таблицу clients любые изменения. Пройдут сутки, и сервер Oracle скопирует через шлюз TGDB2400 целиком всю таблицу clients в customers и будет повторять эту процедуру и далее с интервалом в сутки. Разумеется, интервал времени между копированиями может быть установлен так, как это необходимо, непосредственно при создании снимка либо используя оператор ALTER SNAPSHOT.
Таким образом, мы добились того, что данные периодически передаются из исходной таблицы на интеграционный сервер. Приложение может читать данные из снимка, считая, что, во-первых, оно имеет дело с самой свежей версией данных, полученных на это время, и, во-вторых, что эти данные находятся в БД Oracle.
Однако этого недостаточно. Хотелось бы, чтобы из целевой системы на интеграционный сервер передавались не все данные, а только изменения в данных, накопленные с момента последнего обновления снимка. Цель вполне понятна уменьшить сетевой трафик Передача изменений по сравнению с передачей всего массива данных позволяет существенно разгрузить сеть, так как в целом объем передаваемых по сети таблиц может быть очень велик.
Казалось бы, Oracle позволяет создать моментальный снимок с передачей только изменений (режим FAST REFRESH). Однако не все так просто. Дело в том, что этот режим можно использовать только в том случае, когда в целевой системе определен и используется некоторый механизм накопления изменений в главной таблице и их отображения в снимке.
Предположим первоначально, что исходная БД это база данных Oracle. Тогда все выглядит просто. В целевой системе создается (оператором CREATE SNAPESHOT LOG) журнал снимков (snapshot log). Это таблица, ассоциированная с главной таблицей. Сервер Oracle (в составе целевой системы) сохраняет изменения, выполненные в главной таблице, в журнале снимков, и затем использует его для обновления снимков, ассоциированных с данной главной таблицей. То есть ответственность за накопление и передачу изменений берет на себя сервер Oracle. К сожалению, в данном пилотном проекте этот подход использовать мы не могли, так как целевая система представляла собой DB2/400.
Репликация данных из других систем
Однако и в этой ситуации было найдено решение. Выше мы уже говорили, что семейство Oracle Open Gateways включает группу продуктов Replication Service. Продукт Oracle Replication Service for Data Propogator (ORSDP) позволяет решить поставленную задачу, то есть реплицировать только изменения в исходных таблицах целевой системы (DB2/MVS и DB2/400), но не все содержимое таблиц целиком. Конфигурация соответствующих программных средств представлена на рис. 7.
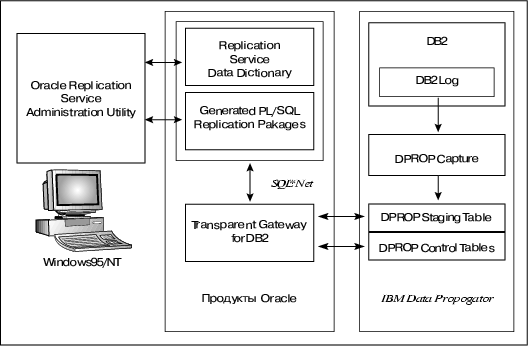
Рис. 7. Схема инкрементальной репликации данных из DB2 в Oracle.
Конфигурация включает следующие компоненты:
- Oracle Replication Services for DataPropogator;
- Oracle Server (на интеграционном сервере);
- Oracle Transparent Gateway for DB2/400 (на AS/400);
- IBM DataPropogator Relational Capture/400 DB2/400.
Какие действия необходимо предпринять, чтобы изменения, выполненные над таблицами DB2/400, отразить на таблицы Oracle? Во-первых, необходимо захватывать изменения в таблицах DB2 и где-то их накапливать. Во-вторых, необходимо накопленные изменения периодически применять к таблицам Oracle.
Первое выполняет продукт IBM DataPropogator Relational Capture (DPROP). Конкретно, DPROP сканирует журналы DB2 и помещает захваченные изменения в таблицы DB2/400. Вполне естественно, что эту часть работы осуществляет продукт IBM, понимающий формат журналов DB2/400.
Второе ложится на плечи Oracle Replication Services. Продукт поставляется для ОС Windows NT и Windows95 и устанавливается на отдельную рабочую станцию, которая берет на себя функции консоли для администрирования процесса репликации. Сам процесс переноса изменений в таблицы Oracle выполняется средствами PL/SQL (язык для разработки хранимых процедур Oracle), функционирующими на интеграционном сервере. Они извлекают (pull) изменения из таблиц DB2/400 и применяют их к результирующим таблицам Oracle. Oracle Replication Service также включает утилиты для администрирования окружения DPROP. Отметим, что с помощью Oracle Replication Services for DataPropogator можно реплицировать данные и в обратном направлении, то есть из Oracle в DB2.
Очевидно, почему Oracle Replication Services был разработан в первую очередь для СУБД DB2. Она очень распространена на мэйнфремах, а для AS/400 DB2 это вообще стандарт (собственно, для AS/400 других баз данных, кроме DB2/400, нет). Видимо, в дальнейшем технология Oracle Replication Service будет распространена на другие системы.
Transparent Gateway for Microsoft SQL Server
В отличие от TGDB2400, который может быть установлен только в стационарной конфигурации, прозрачный шлюз к Microsoft SQL Server может работать и как стационарный, и как удаленный.Однако предпочтение все-таки стоит отдать стационарному варианту конфигурации. Причина была указана выше целесообразно унифицировать сетевой протокол прикладного уровня, выбрав SQL*Net, что достигается в стационарном варианте и было использовано в пилотном проекте (полная конфигурация пилотного проекта представлена на рис. 8).
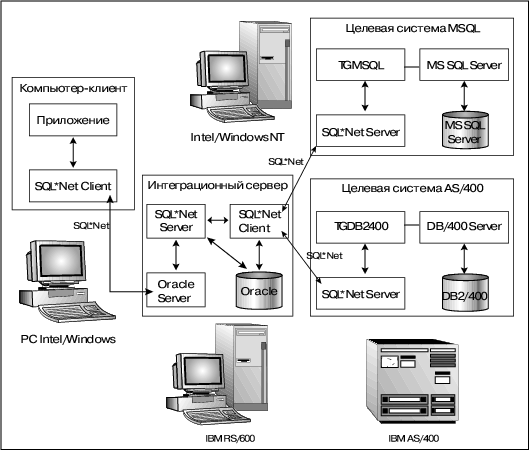
Рис. 8. Полная конфигурация пилотного проекта.
Для организации доступа к Microsoft SQL Server и доставки данных на интеграционный сервер используются описанные выше механизмы (ссылки к базам данных и снимки). Однако в случае Microsoft SQL Server можно использовать только полную репликацию главной таблицы в снимок (режим COMPLETE REFRESH). Мы не можем накапливать изменения в исходных таблицах и передавать их в результирующие, так как для Microsoft SQL Server пока не существует продуктов, аналогичных ORSDP.
Transparent Gateway for ODBC
Допустим, что мы хотели бы разместить компонент унификации доступа на стороне сервера. Кроме того, мы хотели бы использовать для организации доступа к различным БД обобщенный (ODBC) API. В случае ODBC на сервере устанавливаются все компоненты ODBC, описанные выше (кроме, разумеется, приложения), а также Oracle Server и компонент доступа к БД (например, Oracle Transparent Gateway for ODBC TGODBC), транслирующий запросы приложения к базе данных (на Oracle SQL) в запросы на SQL ODBC и направляющий их целевой базе данных. Очевидно, что здесь мы имеем дело с удаленной конфигурацией. Отметим, что пока TGODBC доступен только для Windows NT.
Заключение
По-видимому, технология шлюзов пока была мало известна российским специалистам. Возможно, это объясняется очень небольшим числом по-настоящему интеграционных проектов. Ранее очевидно прослеживалась тенденция образования изолированных "островков информации", вокруг которых и строились технологии обработки данных. Резкое возрастание масштабов проектов и стремление к связыванию островков информации неизбежно востребуют и технологию шлюзов. Арсенал программных продуктов Oracle готов к этому.
Литература
- Middleware: the Key to Distributed Computing. OVUM White Paper , 1996
- Oracle Transparent Gateway for DB2/400 Installation and Users Guide. Release 4.0.1.1 , October 1997
- Oracle Open Gateways. Guide for SQL-Based and Procedural Gateways. Version 4.0 , May 1997
- Oracle Transparent Gateway for Microsoft SQL Server. Installation Guide. Version 4.0.0.2 , August 1997
Статья опубликована в журнале Jet Info, №9-10, 1998 г.